2012 年,一个叫 AlexNet 的模型在 ImageNet 竞赛中碾压所有传统方法,深度学习时代正式开启。
推动这一切的人,叫李飞飞——ImageNet 的缔造者。
十多年后,她的目光早已不在”看图”上。她要让 AI 不只会看,还要会做。
这就是具身智能体(Embodied Agent)。
一、从”看懂”到”做到”
1.1 AI 的三阶段
回顾 AI 的发展,可以分为三个阶段:
| 阶段 | 能力 | 代表技术 | 比喻 |
|---|---|---|---|
| 感知 | 能看懂图片/文字 | CNN, ImageNet | 眼睛 |
| 理解 | 能理解语义和关系 | Transformer, GPT | 大脑 |
| 行动 | 能在环境中完成任务 | Agent, 具身智能 | 双手 |
当前我们正处于从”理解”到”行动”的关键转折点。
1.2 什么是 Agent?
Agent(智能体) 是一个能自主感知环境、做出决策、执行行动的 AI 系统。
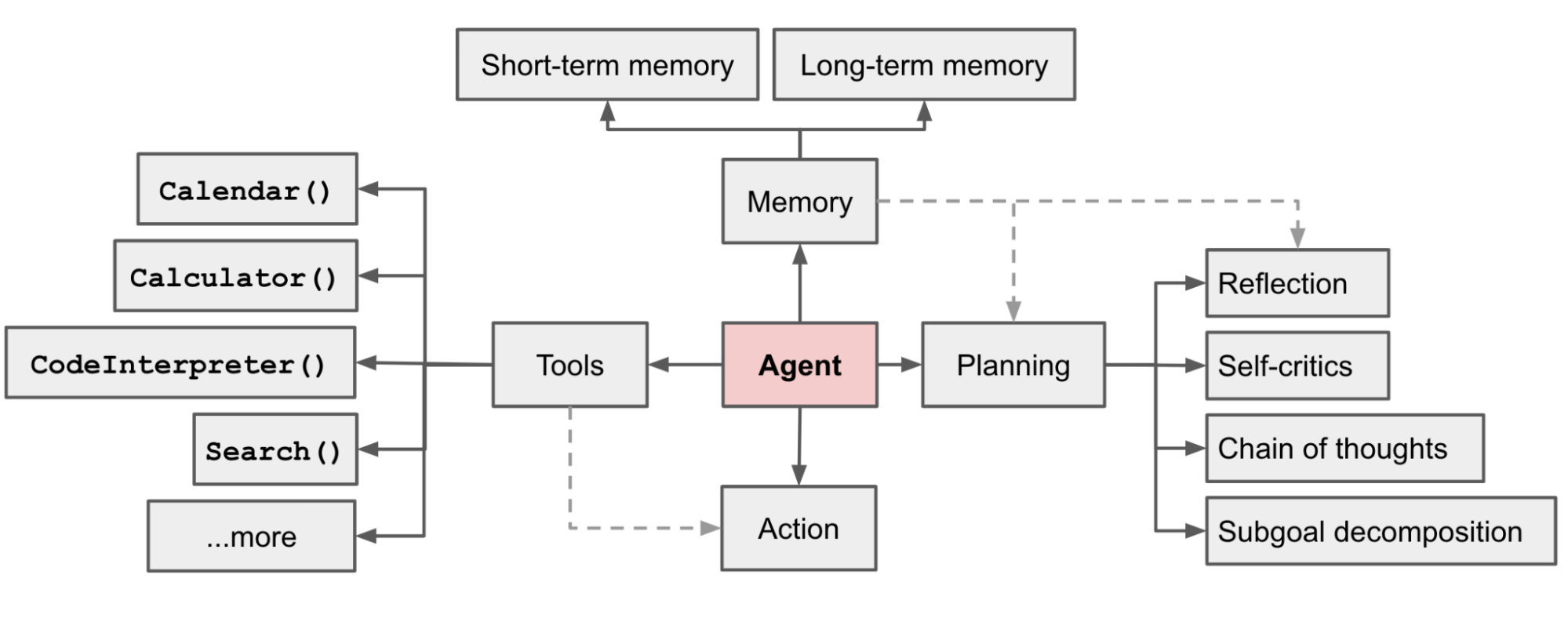
和普通 AI 模型的区别:
| 普通 AI 模型 | Agent 智能体 | |
|---|---|---|
| 输入 | 单次输入 | 持续感知环境 |
| 输出 | 单次输出 | 多步行动序列 |
| 记忆 | 无记忆 | 有短期/长期记忆 |
| 工具 | 不能用工具 | 可以调用工具 |
| 目标 | 回答问题 | 完成任务 |
打个比方:
普通 AI 就像一个字典——你问它什么,它回答什么。
Agent 就像一个管家——你说”帮我打扫房间”,它自己规划怎么做,然后动手干活。
1.3 李飞飞的愿景
2024 年,李飞飞在多个场合提出:
空间智能(Spatial Intelligence)是通向 AGI 的关键路径。
什么意思?
就是 AI 不仅要能理解文本和图片,还要能理解三维空间——知道物体在哪里、怎么移动、如何交互。

这才是让 AI 真正”活”在物理世界中的关键。
二、李飞飞团队的核心贡献
2.1 ImageNet:一切的起点
在谈 Agent 之前,必须先说 ImageNet。

| 年份 | 事件 |
|---|---|
| 2007 | 李飞飞开始构建 ImageNet |
| 2009 | ImageNet 发布,包含 1500 万张标注图片 |
| 2012 | AlexNet 在 ImageNet 上碾压传统方法,深度学习爆发 |
| 2015 | ResNet 在 ImageNet 上超越人类水平 |
没有 ImageNet,就没有今天的深度学习,更没有今天的 Agent。
2.2 BEHAVIOR:让 Agent 有”家务能力”
2021 年,李飞飞团队提出了 BEHAVIOR 基准测试。

BEHAVIOR 的全称是 Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments。
简单说——
在虚拟环境里测试 AI 能不能完成日常家务:做饭、洗碗、叠衣服、打扫卫生…
为什么这很重要?
因为之前的 AI 测试都是”做题”(回答问题、分类图片),而 BEHAVIOR 是”干活”——让 AI 在三维模拟环境中真正操作物体。
| 任务类型 | 示例 |
|---|---|
| 清洁类 | 打扫厨房、洗碗、擦桌子 |
| 烹饪类 | 做三明治、煮咖啡、切菜 |
| 收纳类 | 叠衣服、整理书架、收玩具 |
| 维护类 | 浇花、修东西、换灯泡 |
BEHAVIOR 包含 1000+ 种日常任务,是当时最大的具身智能测试平台。
2.3 VoxPoser:用语言指挥机器人
2023 年,李飞飞团队发表了 VoxPoser。

VoxPoser 的核心思想:
用大语言模型(LLM) 理解自然语言指令,然后生成三维空间中的操作约束,指导机器人完成任务。
举个例子:
人类指令:"把杯子放在盘子旁边"
LLM 理解:
- "杯子" → 物体 A
- "盘子" → 物体 B
- "旁边" → 空间关系约束
生成操作:
- 抓取物体 A
- 移动到物体 B 的旁边位置(约 10cm 偏移)
- 放下VoxPoser 的创新在于:
- 不需要专门训练:用 LLM 的知识直接理解空间关系
- 零样本泛化:没见过的任务也能做
- 可解释:每一步都有明确的空间约束
2.4 3D-LLM:让语言模型理解三维世界
传统的 LLM 只能处理文本,但真实世界是三维的。
李飞飞团队提出了 3D-LLM——一个能理解三维场景的语言模型。

3D-LLM 能做什么?
| 能力 | 示例 |
|---|---|
| 3D 问答 | ”客厅里有几把椅子?“ |
| 空间推理 | ”书架在桌子的哪个方向?“ |
| 导航指令 | ”从门口走到窗户旁边” |
| 操作规划 | ”把红色的杯子放到桌上” |
这就像给 LLM 装上了一双三维的眼睛,让它真正”看懂”物理空间。
三、Agent 的技术架构
3.1 感知模块
Agent 首先需要感知环境:
环境输入
│
├── 视觉:摄像头图像、深度图
├── 语言:自然语言指令
└── 触觉:力传感器反馈
│
▼
感知模块
│
├── 物体识别:这是什么?
├── 场景理解:环境是什么样的?
└── 状态估计:物体在哪里?什么状态?3.2 规划模块
感知之后,Agent 需要规划行动:
目标:"把杯子放到桌上"
│
▼
高层规划:找到杯子 → 抓取杯子 → 移动到桌上 → 放下
│
▼
底层规划:具体的手臂轨迹、力度控制李飞飞团队发现,LLM 是天然的规划器——它能理解复杂指令,分解成可执行的步骤。
3.3 记忆模块
Agent 需要记住之前做过什么:
| 记忆类型 | 作用 | 例子 |
|---|---|---|
| 工作记忆 | 当前任务的临时信息 | ”正在拿杯子” |
| 情景记忆 | 过去的经历 | ”上次做饭烧焦了锅” |
| 语义记忆 | 通用知识 | ”杯子是用来装水的” |
3.4 执行模块
最后,Agent 需要执行行动:

在虚拟环境中,用物理引擎模拟真实世界。
在真实世界中,用机器人硬件执行操作。
四、World Labs:空间智能的未来
2024 年,李飞飞创立了 World Labs,专注于空间智能。

World Labs 的目标:
让 AI 理解三维世界的物理规律,能够在三维空间中推理和行动。
核心技术方向:
| 方向 | 说明 |
|---|---|
| 3D 场景重建 | 从少量图片生成完整三维场景 |
| 空间推理 | 理解物体之间的空间关系 |
| 物理模拟 | 理解重力、碰撞等物理规律 |
| 交互生成 | 生成与环境交互的行动序列 |
这意味着什么?
未来的 AI 不只是聊天机器人,而是能在物理世界中帮你做事的智能体。
想象一下:
- 你说”帮我整理书架”,AI 机器人真的去整理
- 你说”做个番茄炒蛋”,AI 厨师真的去做
- 你说”把房间打扫干净”,AI 清洁工开始工作
五、Agent 的应用场景
5.1 家庭服务
| 场景 | Agent 能做什么 |
|---|---|
| 烹饪 | 根据菜谱自动做饭 |
| 清洁 | 规划清洁路线,打扫房间 |
| 照顾 | 看护老人、陪伴小孩 |
| 维修 | 检查设备故障,简单维修 |
5.2 工业制造
| 场景 | Agent 能做什么 |
|---|---|
| 装配 | 自动组装零件 |
| 质检 | 检查产品质量 |
| 搬运 | 自动搬运物料 |
| 巡检 | 检查设备状态 |
5.3 医疗健康
| 场景 | Agent 能做什么 |
|---|---|
| 手术辅助 | 辅助医生完成精细手术 |
| 康复训练 | 指导患者做康复运动 |
| 药物递送 | 自动送药到病房 |
| 环境消毒 | 自动消毒杀菌 |
六、挑战与展望
6.1 当前挑战
Agent 还面临很多挑战:
| 挑战 | 说明 |
|---|---|
| 泛化能力 | 在 A 环境学会的技能,到 B 环境就不灵了 |
| 安全性 | 机器人操作可能造成物理伤害 |
| 长程规划 | 复杂任务的规划还不够好 |
| 真实世界差距 | 仿真环境和真实世界有差距 |
6.2 李飞飞的预测
李飞飞在 2024 年的演讲中说:
未来 5-10 年,Agent 将从实验室走向千家万户。
她认为:
- 空间智能是下一个突破点
- 多模态融合(视觉+语言+触觉)是关键
- 安全可控是前提条件
- 人机协作是最终形态——不是取代人,而是帮助人
七、总结
Agent 智能体的核心要点:
- 从看懂到做到:AI 不只是回答问题,而是完成任务
- 空间智能:理解三维世界是具身智能的关键
- BEHAVIOR:在虚拟环境中测试 Agent 的家务能力
- VoxPoser:用语言指挥机器人,零样本泛化
- 3D-LLM:让语言模型理解三维空间
- World Labs:李飞飞的空间智能创业公司
记住这句话:
Agent 的本质是让 AI 从”思考者”变成”行动者”。
就像人类不只是用大脑思考,还要用手去创造——Agent 就是 AI 的”手”和”脚”。
参考文献:
- Li Fei-Fei et al., “ImageNet: A Large-Scale Hierarchical Image Database”, CVPR 2009
- Srivastava et al., “BEHAVIOR: Benchmark for Everyday Household Activities”, ICLR 2022
- Huang et al., “VoxPoser: Composable 3D Value Maps for Robotic Manipulation”, CoRL 2023
- Hong et al., “3D-LLM: Injecting the 3D World into Large Language Models”, NeurIPS 2023
- Li Fei-Fei, “World Labs: Spatial Intelligence as the Path to AGI”, 2024