如果你关注 AI,一定听过这些名字:GPT、BERT、LLaMA、Claude…
它们背后都有一个共同的”心脏”——Transformer。
今天用最通俗的语言,带你从零理解这个改变世界的架构。
一、为什么需要 Transformer?
1.1 传统方法的困境
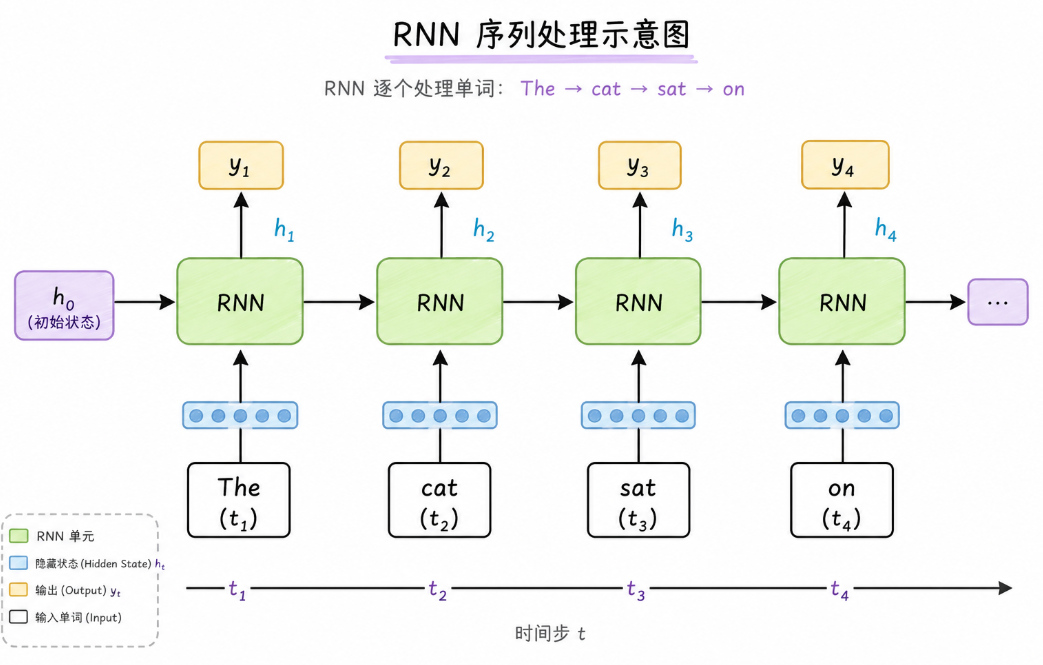
在 Transformer 之前,处理文本主要靠 RNN(循环神经网络)。
RNN 的问题:
| 问题 | 说明 |
|---|---|
| 记性差 | 处理到第 100 个词时,已经忘了第 1 个词是什么 |
| 速度慢 | 必须一个一个词处理,无法并行计算 |
| 长文本崩溃 | 文本越长,信息丢失越严重 |
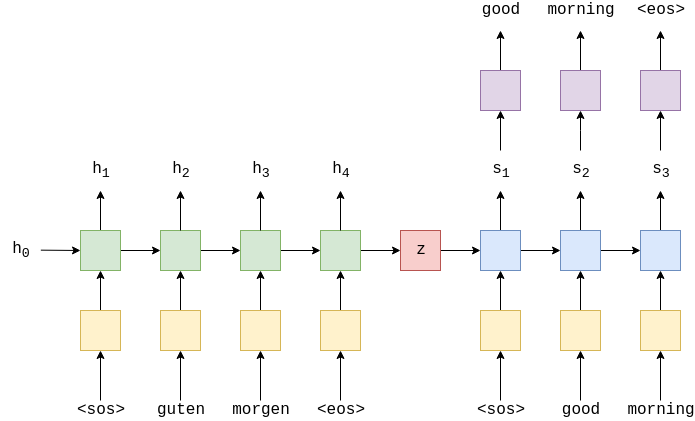
1.2 Transformer 的革命
2017 年,Google 发了一篇论文:“Attention Is All You Need”。
Transformer 的核心思想:
不用一个一个词看了,一次性看完全文,然后自己决定哪些词重要。
就像你阅读一段话时,眼睛会自动聚焦到关键词上——Transformer 做的是同样的事。
二、Transformer 的核心概念
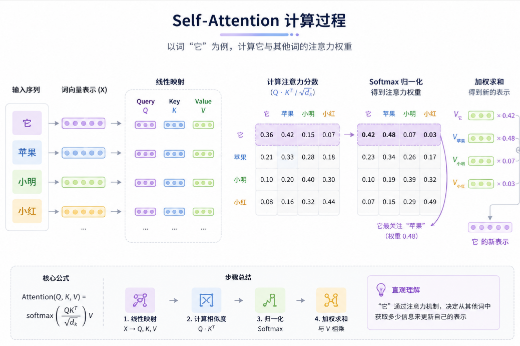
2.1 Self-Attention(自注意力机制)
这是 Transformer 最核心的创新。
什么是自注意力?
举个例子:
“小明把苹果给了小红,它很甜。”
“它”指的是谁?是苹果。
人类一眼就能看出来,但机器怎么知道?
自注意力就是让每个词去”看”其他所有词,然后计算它们之间的关系。
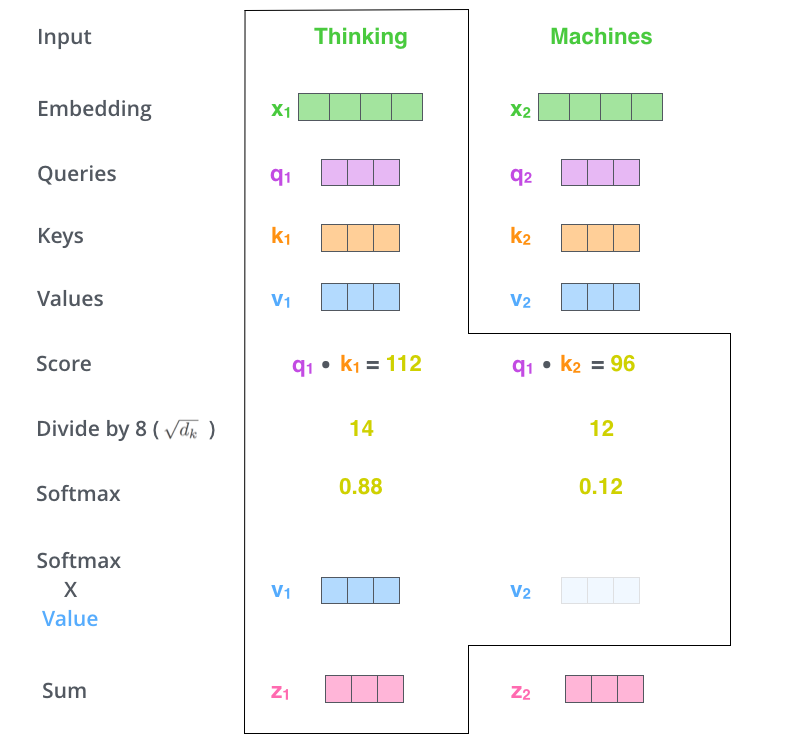
具体怎么计算?
1. 每个词生成三个向量:Query(查询)、Key(键)、Value(值)
2. 用 Query 和 Key 计算相似度
3. 相似度高的词,权重就大
4. 用权重对 Value 加权求和通俗理解:
- Query:我在找什么?
- Key:我是什么?
- Value:我的内容是什么?
2.2 Multi-Head Attention(多头注意力)
为什么叫”多头”?
因为 Transformer 不是只用一组 QKV,而是用多组同时计算。

比如用 8 个”头”,每个头关注不同的东西:
- 头 1:关注语法关系(主语-谓语)
- 头 2:关注语义关系(同义词)
- 头 3:关注位置关系(相邻词)
- …
最后把 8 个头的结果拼接起来,得到更全面的理解。
2.3 位置编码(Positional Encoding)
Transformer 一次性看所有词,但它怎么知道词的顺序?
答案:位置编码。
给每个词加一个”位置标签”,告诉模型这个词在第几位。
输入 = 词向量 + 位置编码就像排队时每个人戴一个号码牌,机器就知道谁在前谁在后了。
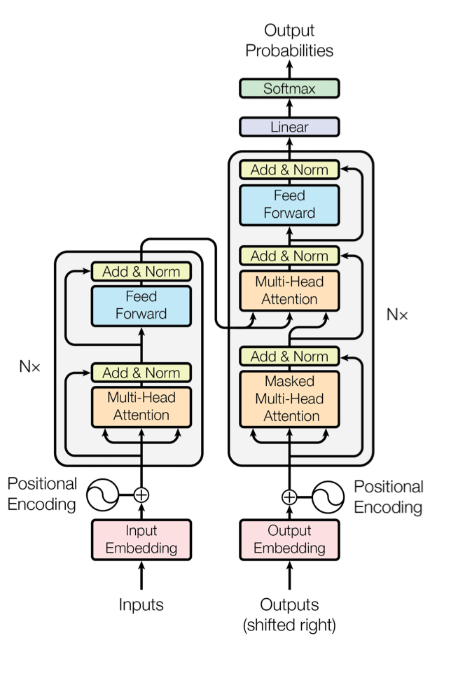
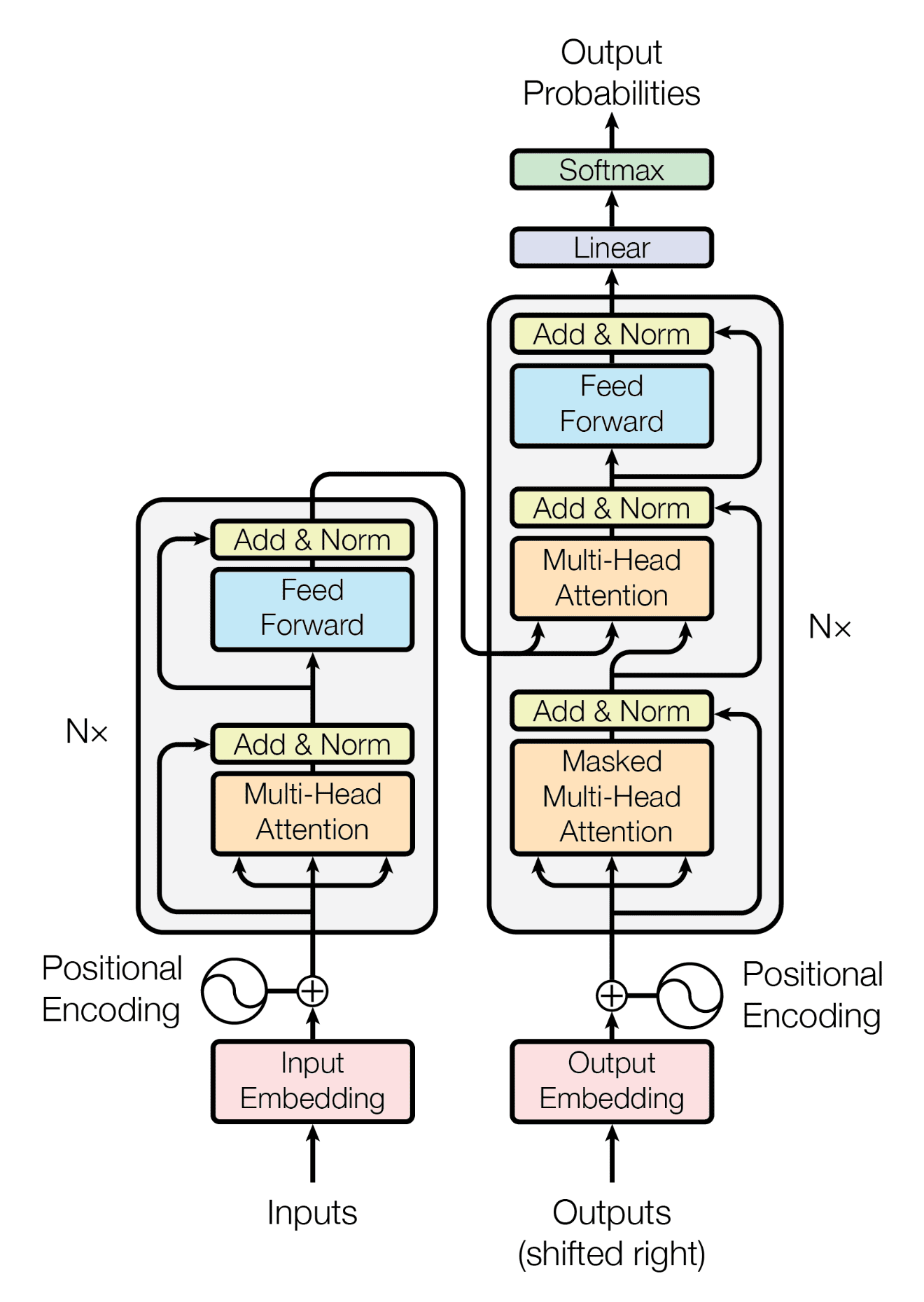
三、Transformer 的整体架构
3.1 两大组件
Transformer 由两部分组成:
┌─────────────────┐ ┌─────────────────┐
│ Encoder │ │ Decoder │
│ (编码器) │ │ (解码器) │
│ │ │ │
│ 理解输入文本 │ │ 生成输出文本 │
└─────────────────┘ └─────────────────┘- Encoder:理解输入(比如理解一句英文)
- Decoder:生成输出(比如翻译成中文)
3.2 Encoder 结构
Encoder 内部是这样的:
输入 → [Self-Attention] → [Feed Forward] → 输出
↑ ↑
残差连接 + 归一化 残差连接 + 归一化关键点:
- Self-Attention:让每个词看到所有词
- Feed Forward:对注意力结果做进一步处理
- 残差连接:防止梯度消失,让信息直接传递
- 归一化:稳定训练过程
这个模块重复 N 次(原论文用了 6 层)。
3.3 Decoder 结构
Decoder 比 Encoder 多了一个东西:Masked Attention。
为什么需要 Mask?
因为生成文本时,你不能”偷看”后面的词。
就像考试时,你不能看后面同学的答案。
生成第 1 个词 → 只能看第 1 个词
生成第 2 个词 → 能看第 1、2 个词
生成第 3 个词 → 能看第 1、2、3 个词
......四、不同类型的应用
4.1 只用 Encoder:BERT
BERT 只用了 Transformer 的 Encoder 部分。
适合理解任务:
- 文本分类
- 情感分析
- 问答系统
4.2 只用 Decoder:GPT
GPT 只用了 Transformer 的 Decoder 部分。
适合生成任务:
- 文本生成
- 对话系统
- 代码生成
4.3 Encoder + Decoder:原始 Transformer
原始 Transformer 两部分都用。
适合序列到序列任务:
- 机器翻译
- 文本摘要
- 语音识别
五、为什么 Transformer 这么强?
5.1 并行计算
RNN 必须一个一个词处理,Transformer 可以同时处理所有词。
这意味着:
- 训练速度快几十倍
- 可以处理更长的文本
- 可以用更大的数据集
5.2 长距离依赖
RNN 处理长文本时,前面的信息会”遗忘”。
Transformer 的自注意力机制,让每个词都能直接看到其他所有词,不管距离多远。
5.3 可扩展性
Transformer 架构天然适合”堆叠”:
- 层数越多,模型越强
- 参数越多,能力越强
- 数据越多,效果越好
这就是为什么 GPT-4 能有万亿参数。
六、动手实践推荐
想深入理解 Transformer?推荐这些资源:
| 资源 | 作者 | 特点 |
|---|---|---|
| The Annotated Transformer | Harvard NLP | 逐行代码注释 |
| nanoGPT | Andrej Karpathy | 最简实现,200 行代码 |
| minGPT | Andrej Karpathy | 教学级实现 |
| 3Blue1Brown 视频 | 3Blue1Brown | 最佳可视化讲解 |
| Lilian Weng 博客 | Lilian Weng | 深度技术解析 |
七、总结
Transformer 的核心要点:
- Self-Attention:让每个词看到所有词,计算关系
- Multi-Head:多角度理解文本
- Positional Encoding:告诉模型词的顺序
- Encoder-Decoder:理解 + 生成
- 并行计算:比 RNN 快几十倍
记住这句话:
Transformer 的本质是让模型学会”看哪里”。
就像人类阅读时会自动聚焦重点,Transformer 学会了把注意力放在最重要的词上。
参考文献:
- Vaswani et al., “Attention Is All You Need”, NeurIPS 2017
- Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers”, NAACL 2019
- Radford et al., “Language Models are Unsupervised Multitask Learners”, OpenAI 2019